
Sur Google, chercher OpenHuman ne vise généralement pas un article académique, mais trois réponses pratiques : Qu’est-ce qu’OpenHuman ?, L’installation en vaut-elle la peine ? (un OpenHuman review honnête) et Comment l’installer ? (OpenHuman install / OpenHuman tutorial). Cette page est le guide pilier OpenHuman de Hashvps — une entrée complète couvrant l’installation, OpenHuman Long-Term Memory, le Memory Tree, les comparaisons avec ChatGPT / Mem0 / OpenClaw / Claude Projects, des scénarios d’usage réels et ce qu’il faut faire lorsque votre Personal AI doit rester joignable vingt-quatre heures sur vingt-quatre. Les futurs articles détaillés sur les runbooks d’installation et l’architecture mémoire renverront ici.
En une phrase : OpenHuman compte parmi les parcours Personal AI les plus discutés en 2026 — un OpenHuman Desktop Agent open source qui se déploie comme un OpenHuman AI Assistant complet, transforme e-mail, code et calendrier en mémoire à long terme locale et vous épargne de vous présenter à nouveau chaque lundi matin.
La version en 30 secondes :
-
OpenHuman Personal AI
Un OpenHuman AI Assistant de bureau qui connecte Gmail, GitHub et bien plus via OAuth, puis construit OpenHuman Long-Term Memory sur votre machine.
Local-first
-
Installer avant de juger
Suivez le tutoriel d’installation OpenHuman ci-dessous ; la plupart des utilisateurs obtiennent une première synchronisation en environ quinze minutes. Ne vous fiez pas aux seuls articles d’architecture.
Install / Setup
-
Always-on est un problème séparé
Fermer le capot du portable met la synchronisation en pause. Pour un fonctionnement 7×24 sur un canal, lisez la section finale — le matériel cloud n’est pas un prérequis pour démarrer avec OpenHuman.
Limites → options
1. Qu’est-ce qu’OpenHuman ?
OpenHuman est la pile open source de TinyHumans AI pour la Personal AI super intelligence. Le slogan officiel — Private, Simple, Extremely powerful — décrit un produit concret : un OpenHuman Desktop Agent (Rust + Tauri) pour macOS, Windows ou Linux, avec une interface OpenHuman AI Assistant intégrée, plus de 118 intégrations tierces et une base de connaissances locale Memory Tree. Ce n’est pas une autre surcouche navigateur sur ChatGPT.
OpenHuman s’inscrit dans le récit du « jumeau numérique IA personnel » d’une manière précise : vous pouvez changer de modèle sous-jacent (Claude, GPT et autres), mais OpenHuman accumule en continu qui vous êtes et sur quoi vous travaillez. La mémoire reste par défaut sur votre machine — SQLite plus un vault Markdown que vous pouvez lire, comparer et sauvegarder. Certains flux de connexion et d’intégrations managées passent par le backend de TinyHumans ; lisez les notes Local + managed de la README avant votre première autorisation OAuth.
Pour les internautes francophones, « Qu’est-ce qu’OpenHuman ? » s’accompagne souvent de questions sur la confidentialité et le contrôle. Contrairement à un assistant SaaS pur, le OpenHuman Desktop Agent produit des artefacts visibles dans le système de fichiers : des fichiers vault pour Obsidian, une base de données à snapshotter avant les mises à jour et des scopes d’intégration que vous autorisez service par service. Cette posture local-first explique pourquoi les développeurs comparent OpenHuman aux SDK mémoire et aux stacks gateway plutôt qu’à un seul abonnement chat.
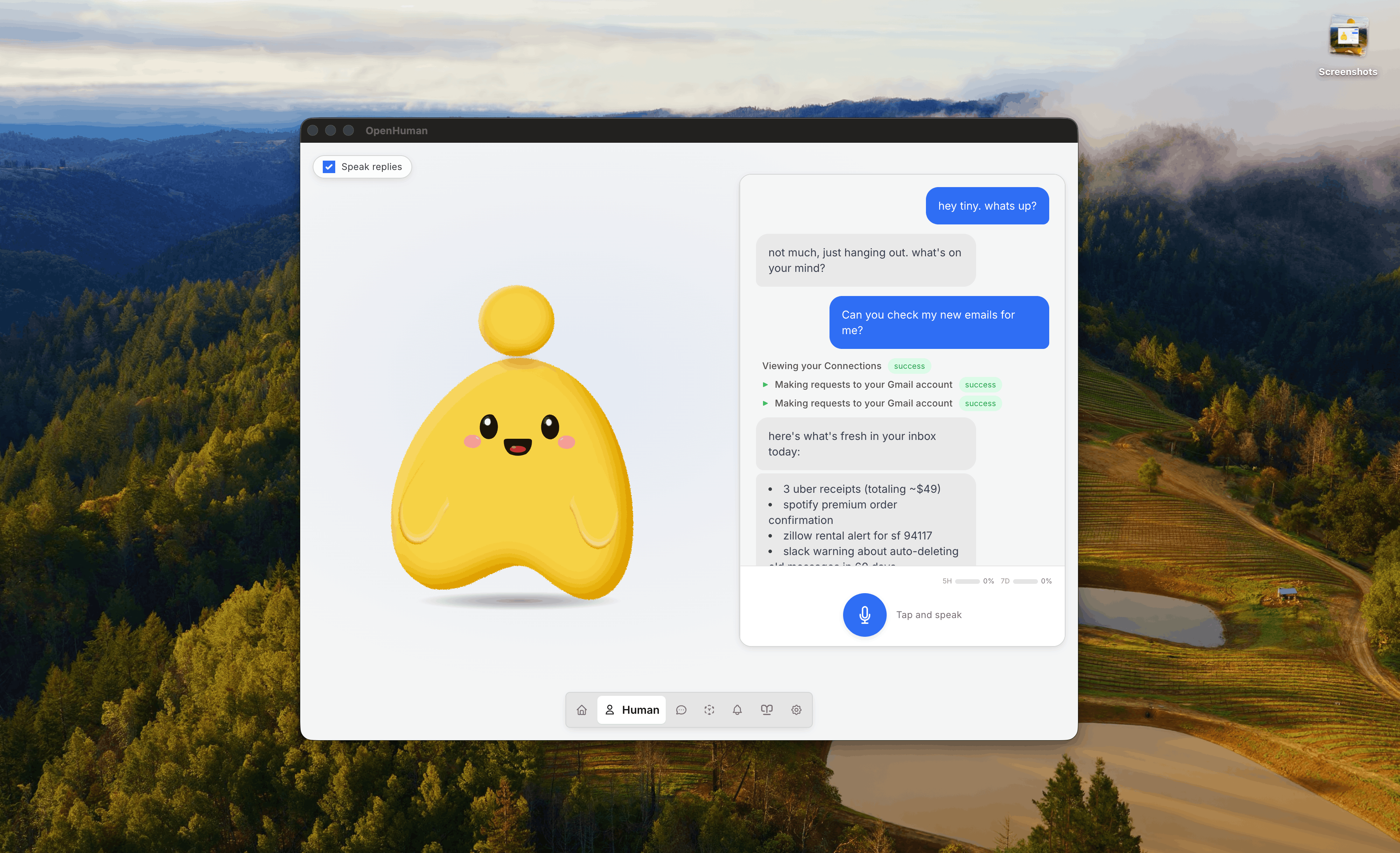
Si vous n’avez utilisé que le chat web, le changement de modèle mental mérite d’être nommé clairement : OpenHuman est une application Personal AI résidente, pas un favori. Elle exécute des jobs auto-fetch en arrière-plan, maintient une couche mémoire structurée et injecte ce contexte lorsque vous posez une question au OpenHuman AI Assistant des jours plus tard. Le modèle répond ; OpenHuman apporte la continuité.
2. Pourquoi OpenHuman est tendance
Début 2026, OpenHuman a dépassé trente mille étoiles GitHub et est apparu sur Trendshift et Product Hunt parce qu’il est arrivé au cœur d’une vague de recherche Personal AI. Les utilisateurs voulaient moins un modèle cinq pour cent meilleur aux benchmarks que OpenHuman Long-Term Memory — la capacité de demander mercredi : « Qu’avons-nous convenu avec le client A sur les callbacks de paiement ? » et d’obtenir une réponse ancrée dans l’e-mail de lundi, et non dans ce que vous aviez copié au hasard dans une fenêtre de chat.
- La plupart de ceux qui cherchent
OpenHumanont une intention OpenHuman tutorial ou OpenHuman install ; ils veulent une app exécutable, pas un livre blanc. - La presse technique couvre l’architecture Memory Tree, mais le point d’entrée viral reste : « Installer un Personal AI Assistant qui connaît vraiment ma semaine. »
- Contrairement à ChatGPT Memory seul, OpenHuman tire le contexte de Gmail, GitHub, Slack et calendriers autorisés — pas seulement des phrases tapées dans un seul fil de chat.
- La posture open source réduit le coût d’essai : vous pouvez vérifier si OpenHuman Long-Term Memory correspond à votre workflow avant de vous lier à une stack cloud always-on.
Un autre moteur est la fatigue de la réintroduction du contexte. Les travailleurs du savoir vivent dans cinq onglets SaaS ; chaque onglet détient un morceau de vérité, et aucun ne parle à votre chatbot générique sauf si vous exportez et uploadez manuellement. Le pari d’OpenHuman : auto-fetch plus mémoire locale bat un autre « modèle de prompt » pour les personnes qui coulent déjà sous le bruit des boîtes mail et des trackers d’issues.
![]()
Le statut tendance attire aussi les sceptiques — à juste titre. Un logiciel Early Beta évolue vite ; les intégrations cassent ; les résumés deviennent bruyants si vous connectez tout le premier jour. Le buzz signale que la Personal AI à mémoire durable est une vraie catégorie, pas que chaque installation fonctionnera magiquement dès la première heure. C’est pourquoi ce guide combine enthousiasme, étapes d’installation, tableaux comparatifs et limites honnêtes à la section 11.
3. OpenHuman AI Assistant : fonctionnalités clés
Considérez le OpenHuman AI Assistant comme un copilote de bureau à mémoire long terme. Dans un OpenHuman review, vous devriez vraiment tester ces cinq capacités la première semaine :
- Onboarding UI-first : Assistant d’installation court, pas de YAML dès le départ. Correspond à la recherche OpenHuman setup — ouvrir l’app, connecter les services, poser des questions.
- 118+ intégrations : Gmail, GitHub, Slack, Google Calendar et des dizaines d’autres via OAuth, exposées comme outils que l’agent peut appeler.
- Auto-fetch : Environ toutes les vingt minutes, des pulls incrémentaux alimentent OpenHuman Long-Term Memory sans que vous écriviez de scrapers.
- Memory Tree + Vault : Retrieval machine pour l’agent, Markdown lisible pour vous — y compris des fichiers compatibles Obsidian.
- Persona et voix optionnelles : Mascotte de bureau, modes meeting agent et autres fonctionnalités produit dans la documentation GitBook officielle.
OpenHuman n’est pas un SDK mémoire à intégrer dans votre propre bot. C’est un produit Personal AI complet — une distinction importante lors de la comparaison avec Mem0 ou OpenClaw plus bas.
Opérationnellement, le OpenHuman AI Assistant se situe au centre d’une boucle : les intégrations écritent, le Memory Tree organise, le modèle lit. Vous pouvez toujours apporter vos propres clés API pour les routes Claude ou GPT ; OpenHuman ne vous enferme pas dans un fournisseur d’inférence. Ce qu’il verrouille bien, c’est la continuité sur plusieurs jours. L’assistant se souvient que l’issue #42 et la sync du jeudi existent parce que les jobs fetch les ont ingérées, pas parce que vous avez résumé votre semaine dans un seul prompt du dimanche.
Les power users doivent définir des limites : tokens GitHub en lecture seule, labels Gmail sélectifs, canaux Slack plutôt que workspaces entiers. L’assistant n’est aussi propre que le signal que vous lui donnez. Cette discipline sépare un OpenHuman review précis des articles de blog qui ont connecté douze services à la minute 1 et qualifié la couche mémoire de « bruyante ».
4. Tutoriel d’installation OpenHuman (Install / Setup)
Voici un parcours général OpenHuman install (macOS d’abord ; les builds Windows et Linux figurent dans la README officielle). Les libellés des boutons changent entre releases — faites confiance à l’UI client si quelque chose diverge.
- Téléchargement : Récupérer la dernière build sur tinyhumans.ai/openhuman ou GitHub Releases.
- (Recommandé sur macOS) Homebrew :
brew tap tinyhumansai/core && brew install openhuman - Installer et lancer l’OpenHuman Desktop Agent ; autoriser l’app dans les Réglages système si Gatekeeper macOS le demande.
- Se connecter / créer un workspace ; saisir les clés API modèle si vous n’utilisez pas le routage fourni.
- Integrations → connecter Gmail et vérifier que les résumés mail apparaissent en mémoire.
- Connecter GitHub (lecture seule suffit à beaucoup) ; issues et PR entrent dans le Memory Tree.
- Attendre le premier cycle auto-fetch (prévoir trente à quarante minutes ; ne pas fermer le capot ni éteindre tout de suite).
- Ouvrir les vues Memory / Wiki et vérifier les résumés par source ou date.
- Poser au OpenHuman AI Assistant trois questions-sondes (voir retour d’expérience ci-dessous).
Les tutoriels francophones sautent souvent l’étape d’attente. OpenHuman Long-Term Memory est vide tant que les jobs fetch ne l’ont pas remplie ; condamner le produit après six minutes revient à déclarer l’e-mail cassé avant la fin de la première sync. Planifiez la première session lorsque la machine reste éveillée, connectée et alimentée.
Si Homebrew est votre standard, la chaîne en une ligne brew install openhuman après brew tap tinyhumansai/core est le chemin reproductible le plus rapide pour les équipes qui documentent des runbooks internes OpenHuman setup. Notez la version de release si vous avez besoin de clarté de rollback pendant les cycles Early Beta.
5. Comment fonctionne OpenHuman Long-Term Memory
Quand les utilisateurs parlent de « mémoire locale OpenHuman », ils désignent la pipeline OpenHuman Long-Term Memory — vous n’uploadez pas chaque PDF à la main :
- OAuth autorise une source de données (Gmail, GitHub, etc.).
- Auto-fetch tire des mises à jour incrémentales selon le planning.
- Le contenu est nettoyé, chunké et résumé en plusieurs niveaux pour maîtriser les coûts de tokens.
- Les résultats vont dans SQLite locale (retrieval agent) et un vault Markdown (revue humaine).
- Lors des questions, des résumés pertinents sont injectés au lieu d’un cold start sans contexte.
Cela diffère fondamentalement de « garder l’historique de chat plus longtemps ». La mémoire provient de votre vrai workflow — la même raison pour laquelle les recherches Personal AI, assistant IA personnel et jumeau numérique IA décrivent souvent un besoin : arrêter d’être la couche d’intégration entre apps et modèle.
Côté confidentialité, SQLite locale plus vault signifient que vous pouvez inspecter ce que le système a retenu avant qu’il n’influence une réponse. Supprimer un fichier vault, relancer un fetch ou révoquer OAuth — des actions lourdes ou impossibles quand la mémoire n’existe que dans une fonction cloud opaque du fournisseur. Cette transparence est au cœur de la promesse du OpenHuman Desktop Agent pour les professionnels francophones qui lisent les fils OpenHuman review sur Hacker News ou Reddit.
Le résumé n’est pas magique. Auto-fetch peut manquer des fils, mal pondérer un vieux mail ou sur-compresser une négociation nuancée. Traitez la mémoire injectée comme des notes de haute qualité, pas comme une preuve judiciaire, jusqu’à validation contre les apps sources. Le gain est la vitesse : vous partez d’un brouillon de synthèse plutôt que d’un prompt vide.
6. Qu’est-ce que le Memory Tree ?
Le Memory Tree est la façon d’OpenHuman d’organiser la Long-Term Memory : les données sont structurées à l’écriture par source, thème et vue d’ensemble quotidienne, afin que les requêtes tirent des résumés ciblés au lieu de scanner tout le corpus vectoriel à chaque tour. La plupart des utilisateurs ont besoin de trois idées :
- Par source : un arbre pour le mail, un pour GitHub, un pour Slack.
- Par thème : clients et projets agrégés entre sources.
- Par aujourd’hui : vue d’ensemble « que s’est-il passé aujourd’hui ».
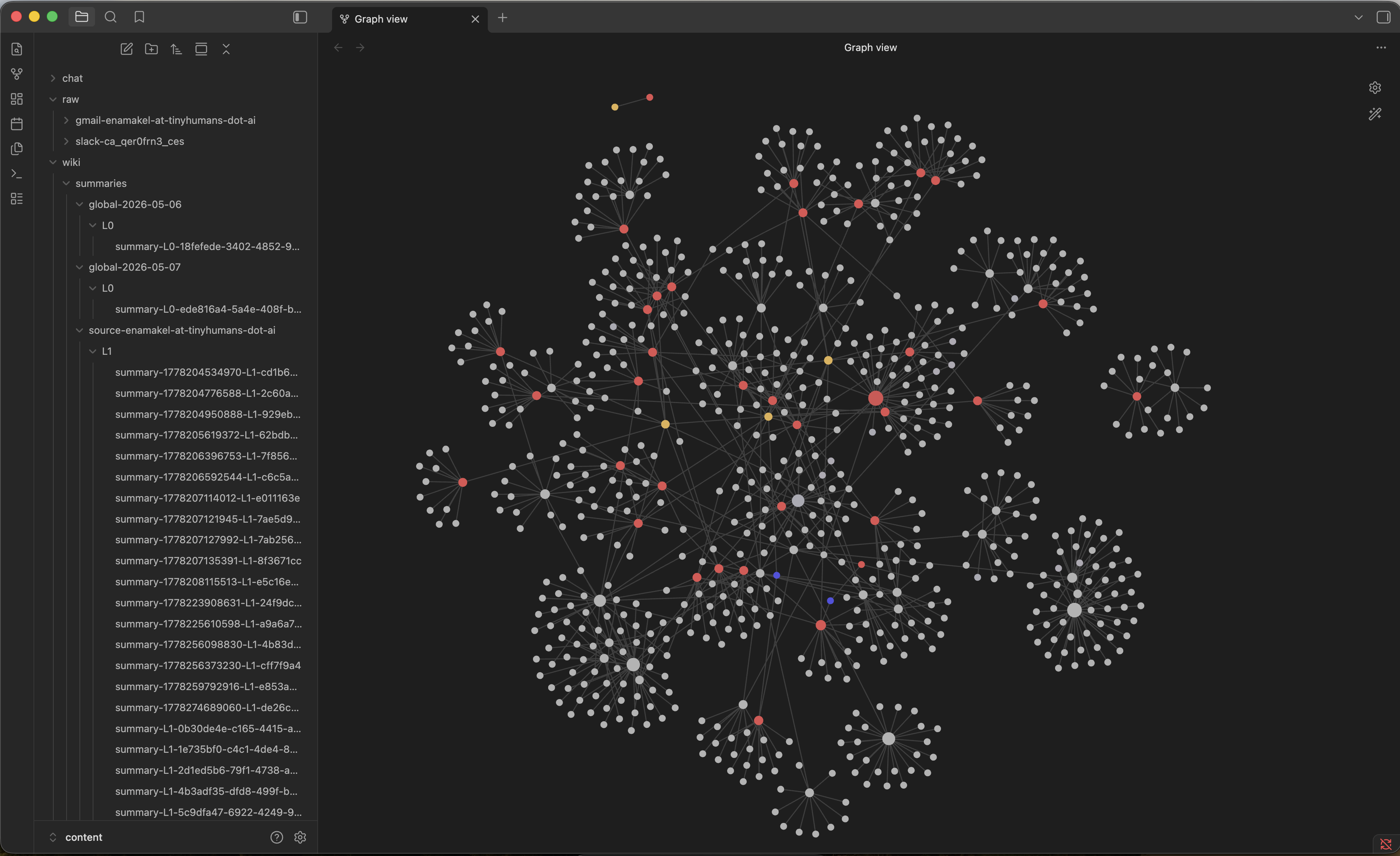
Les développeurs peuvent approfondir les noms buffer, seal et cascade ; qui cherche OpenHuman Memory Tree architecture commence avec le schéma ci-dessus plus la documentation auto-fetch.
Pourquoi structurer à l’ingestion ? Latence et cohérence. Un index d’embeddings plat sur tout ce que vous avez reçu serait flexible mais coûteux et flou. Le Memory Tree échange un peu d’organisation en amont contre des réponses qui ressemblent au bon carnet plutôt qu’à un entrepôt fouillé. Si vous exportez le Markdown vault vers Obsidian, vous voyez le côté lisible humain de la même structure.
Pour les équipes, le Memory Tree clarifie aussi le débogage : si le contexte GitHub est faux, inspectez la branche GitHub de l’arbre au lieu de renégocier toute la stack Personal AI. Cette modularité aide pour les runbooks internes autour du OpenHuman AI Assistant.
7. OpenHuman Desktop Agent vs. ChatGPT
La réponse standard à OpenHuman vs ChatGPT : ChatGPT est un conseiller cloud généraliste ; OpenHuman est un Personal AI Desktop Agent avec OpenHuman Long-Term Memory.
| Dimension | ChatGPT | OpenHuman |
|---|---|---|
| Forme | Navigateur / app mobile | OpenHuman Desktop Agent |
| Mémoire | Historique chat + fonction mémoire fournisseur | OpenHuman Long-Term Memory + auto-fetch multi-sources |
| Emplacement des données | Souvent cloud OpenAI | Vault / SQLite local par défaut |
| Idéal pour | Questions ponctuelles, brouillons texte | Personal AI sur mail / code / calendrier |
ChatGPT reste excellent pour des brouillons rapides, du brainstorming et des tâches où vous injectez tout le contexte inline. OpenHuman gagne quand le contexte vit en dehors de la fenêtre de chat — fils de négociation, commentaires d’issues, décalages de calendrier. Beaucoup d’utilisateurs francophones gardent les deux : ChatGPT pour la vitesse, OpenHuman AI Assistant pour la continuité.
L’intention de recherche compte. Si votre requête est « écris-moi une lettre de motivation », ChatGPT suffit. Si c’est « où en étions-nous sur le pricing avec le client A après le fil de la semaine dernière ? », vous interrogez un produit mémoire — là le OpenHuman Desktop Agent justifie sa place sur disque et les scopes OAuth.
8. Comparaisons concurrentielles : Mem0, OpenClaw, ChatGPT Memory, Claude Projects
8.1 OpenHuman vs. Mem0
OpenHuman vs Mem0 : Mem0 est un SDK mémoire à intégrer dans des agents que vous construisez. OpenHuman est une Personal AI complète avec UI OpenHuman AI Assistant, intégrations et jobs fetch déjà câblés. Mem0 si votre objectif est : « J’écris un bot sur mesure. » OpenHuman si c’est : « Je veux une app qui me connaît après installation. »
Mem0 brille dans des pipelines sur mesure — vous contrôlez les API de retrieval, les backends de stockage et les frameworks agent. OpenHuman échange cette flexibilité contre le time-to-value : boutons OAuth plutôt que design de schéma. Les équipes avec plateformes agent existantes utilisent parfois les deux concepts en parallèle : Mem0 dans le service propriétaire, OpenHuman sur le portable du fondateur pour la continuité personnelle.
8.2 OpenHuman vs. ChatGPT Memory
OpenHuman vs ChatGPT Memory : ChatGPT Memory retient surtout les faits que vous avez mentionnés dans le chat. OpenHuman ingère aussi Gmail, GitHub et autres sources connectées autorisées. Si votre contexte de travail n’a jamais vécu dans le dialogue ChatGPT, OpenHuman Long-Term Memory convient mieux.
ChatGPT Memory a amélioré la classe « souviens-toi que je préfère les puces ». Il ne lit pas automatiquement votre tracker d’issues ou votre boîte de réception sauf si vous copiez le contenu. Pour consultants, fondateurs et staff engineers dont la vérité est dispersée dans le SaaS, c’est précisément le trou que comble le OpenHuman Desktop Agent.
8.3 OpenHuman vs. Claude Projects
OpenHuman vs Claude Projects : Claude Projects est fort quand vous uploadez fichiers et instructions de projet dans l’écosystème Anthropic. OpenHuman est une Personal AI locale qui couvre plus de surfaces SaaS et met à jour le Memory Tree pendant que les jobs fetch tournent. Répartition sensée : Claude pour les longs brouillons dans un dossier projet ; OpenHuman pour « ce qui s’est passé dans mes vrais comptes cette semaine. »
Claude Projects convient aux engagements bornés — un workspace memo juridique, un dossier spec produit. Il est moins automatique pour les systèmes vivants comme e-mail et GitHub qui changent chaque heure. L’auto-fetch d’OpenHuman est le différenciateur pour ceux qui n’uploaderont pas chaque fil à la main.
8.4 OpenHuman vs. OpenClaw
OpenHuman vs OpenClaw ne devrait pas être cadré comme une concurrence directe :
- OpenHuman : Personal AI Assistant de bureau ; force = OpenHuman Long-Term Memory et simplicité install-and-use.
- OpenClaw : Gateway self-hosted + workspace + canaux ; force = exploitation jumeau numérique 7×24 Telegram / Slack sur un Mac qui reste en ligne.
Combinaison optionnelle : OpenHuman en local pour la curation mémoire, puis export de règles haute confiance vers un workspace OpenClaw sur un Mac cloud. Pour le déploiement OpenClaw, voir notre guide jumeau numérique — aucun prérequis pour l’installation OpenHuman.
Les lecteurs francophones découvrent souvent les deux noms la même semaine parce qu’ils touchent tous deux à « Personal AI ». Séparez les couches : OpenHuman = mémoire et UX assistant de bureau ; OpenClaw = résidence, canaux et supervision des processus gateway. On peut aimer l’un, les deux ou aucun — sans contradiction.
9. Retour d’expérience : Before et After
Voici un scénario OpenHuman review représentatif — fictif mais fidèle aux workflows typiques des travailleurs du savoir :
| Phase | Sans OpenHuman | Avec OpenHuman |
|---|---|---|
| Lundi | E-mail fixe le calendrier de paiement ; issue GitHub #42 ouverte ; Slack note un debug commun jeudi | Mêmes événements, désormais dans OpenHuman Long-Term Memory |
| Mercredi | Deadline floue ; fouiller trois apps | Demander au OpenHuman AI Assistant : « Statut paiement client A ? » |
| Réponse | « Merci de fournir le contexte… » | « E-mail a convenu d’un callback async ; #42 ouverte ; debug jeudi au calendrier. » |
Si trois questions-sondes après installation ratent la cible, vérifiez d’abord si la sync est terminée — n’accusez pas tout de suite l’intelligence du modèle.
De bonnes questions-sondes référencent des faits que vous n’avez pas collés dans le chat : un nom de code client, un numéro d’issue, une réunion mentionnée seulement sur Slack. Des sondes faibles (« résume Python ») ne testent pas OpenHuman Long-Term Memory du tout. Un OpenHuman review équitable entraîne la mémoire, pas le trivia général.
Après une semaine réussie, beaucoup rapportent moins de taxe de changement de contexte : moins d’Alt-Tab vers Gmail, moins d’historique d’issues avant le standup. L’assistant ne remplace pas les apps ; il compresse le temps de retrieval. C’est le Before/After qui vaut la peine d’être mesuré si vous décidez si le OpenHuman Desktop Agent mérite une icône permanente dans le dock.
10. Pour qui est OpenHuman ? L’installation en vaut-elle la peine ?
Bon profil : Gros utilisateurs e-mail + GitHub + calendrier ; ceux qui explorent Personal AI / OpenHuman AI Assistant avec la rugosité Early Beta ; personnes qui paient déjà des API modèle et veulent que les appels incluent du contexte réel.
Mauvais profil : Q&A web occasionnelle pure ; conformité enterprise stricte interdisant agents locaux avec OAuth large ; qui exige qu’un portable fermé réponde sur Telegram à 3 h du matin sans infra supplémentaire (voir section 11).
L’installation en vaut-elle la peine ? Si vous êtes dans le premier groupe, suivez la section 4 et testez deux semaines. Si vous gagnez plus de temps en évitant le saut d’apps que coûtent install et réglages, gardez-le. Sinon désinstallez proprement et révoquez OAuth — pas de piège du coût irrécupérable.
Étudiants et hobbyistes peuvent utiliser OpenHuman comme terrain d’apprentissage mémoire Personal AI, mais le produit brille sur des workflows multi-apps soutenus. Fondateurs solo, developer advocates, leads customer success et consultants indépendants ressentent souvent la douleur en premier parce qu’ils sont leur propre couche d’intégration.
Les acheteurs enterprise devraient planifier un pilote, pas un déploiement fleet : politique de backup, revue de résidence des données et scopes OAuth acceptables nécessitent un go interne. OpenHuman est open source, ce qui facilite l’inspection, mais le rythme Early Beta signifie : ne pas le traiter comme source de vérité unique sans exports et vérification humaine.
11. Options always-on : limites OpenHuman et solutions
D’abord la logique, ensuite l’infra — pour que ce guide ne ressemble pas à un pitch serveur déguisé en tutoriel OpenHuman.
11.1 Limites OpenHuman (forme, pas échec)
- Capot fermé → auto-fetch en pause ; le OpenHuman AI Assistant n’est pas joignable comme service résident.
- OAuth expiré ou disque plein → vous croyez la mémoire à jour, mais le Memory Tree s’est arrêté silencieusement.
- Plusieurs appareils → deux silos mémoire, sauf si vous concevez une sync ou choisissez une machine canonique.
- Early Beta → sauvegarder avant upgrades ; ne pas traiter les snapshots vault comme vérité production immuable.
Rien de cela n’annule la valeur Personal AI sur la workstation principale. Cela définit où le OpenHuman Desktop Agent s’arrête et où commence l’ingénierie always-on.
11.2 Quand avez-vous vraiment besoin d’always-on ?
Seulement si vous n’êtes pas au clavier mais une Personal AI doit répondre aux messages, exécuter des schedules ou accepter des webhooks — classique : garde de nuit Telegram pendant que vous dormez. OpenHuman desktop seul ne résout pas la résidence ; il résout la mémoire tant que la machine est éveillée.
Always-on est une intention de recherche différente de « Qu’est-ce qu’OpenHuman ? » ou « OpenHuman install ». Reconnaissez la bifurcation tôt pour ne pas rejeter un produit mémoire parce qu’il ne joue pas gateway 7×24 sans setup supplémentaire.
11.3 Parcours courants (du plus léger au plus lourd)
- Capot ouvert avec alimentation externe : Coût le plus bas ; convient au télétravail qui peut laisser un Mac éveillé.
- Mac mini dédié à la maison : Déplacer l’OpenHuman Desktop Agent sur un Mac toujours branché ; accéder au portable en remote desktop en déplacement.
- Mac dédié cloud : Pendant que vous voyagez capot fermé, un Mac distant continue sync et exécution — pour utilisateurs qui hébergent déjà des workloads macOS off-prem.
Hashvps propose le troisième schéma comme hôtes Mac cloud macOS (bare metal M4 Canada, IP dédiées) — utile pour workloads macOS 7×24 que certaines équipes font tourner aux côtés de gateway OpenClaw, build runners ou agents distants. Ce n’est pas requis pour OpenHuman. La plupart des lecteurs installent en local, prouvent que OpenHuman Long-Term Memory aide, puis décident si la résidence en ligne payante mérite une ligne budgétaire à part.
Si vous choisissez plus tard OpenClaw pour l’exploitation jumeau multi-canal plus Mac cloud, lisez le guide d’installation headless ; il complète la couche mémoire d’OpenHuman au lieu de la remplacer.
12. Résumé
Ce guide complet OpenHuman se résume en une phrase : Qu’est-ce qu’OpenHuman ? → Un Personal AI Desktop Agent / OpenHuman AI Assistant autour de OpenHuman Long-Term Memory et du Memory Tree. Installation via section 4 ; comprendre la mémoire aux sections 5–6 ; choisir les alternatives en 7–8 ; juger la valeur en 9–10 ; capot fermé et always-on en section 11. Cette page est l’entrée pilier — les futurs articles sur les edge cases OpenHuman install et les deep dives Memory Tree renverront ici.
Le trafic de recherche francophone se regroupe autour de verbes pratiques : installer, review, versus ChatGPT. Ce guide répond directement et nomme assez d’architecture pour que vous ne soyez pas surpris au troisième jour. Gardez l’app si la mémoire fait gagner du temps ; ajoutez de l’infra seulement quand la résidence devient une exigence réelle, pas hypothétique.
13. Foire aux questions (FAQ)
F1. Qu’est-ce qu’OpenHuman ? Quel lien avec Personal AI ?
OpenHuman est un produit Personal AI open source. Le OpenHuman AI Assistant est l’interface conversationnelle ; OpenHuman Long-Term Memory est la différence principale face au chat générique.
F2. Comment installer OpenHuman ?
Voir section 4 : téléchargement depuis GitHub Releases ou Homebrew brew install openhuman après brew tap tinyhumansai/core.
F3. OpenHuman en vaut-il la peine ? (OpenHuman review)
Si vous vivez dans e-mail, GitHub et calendriers et détestez répéter le contexte — testez deux semaines. Si vous n’avez besoin que de chat web occasionnel, passez votre chemin.
F4. OpenHuman est-il gratuit ?
Le client est open source. L’inférence modèle et certains services managés peuvent engendrer des coûts ; consultez les tarifs officiels sur les propriétés TinyHumans.
F5. OpenHuman vs. ChatGPT — que choisir ?
ChatGPT pour questions ponctuelles rapides ; le OpenHuman Desktop Agent quand vous avez besoin de OpenHuman Long-Term Memory sur mail, code et calendrier.
F6. Faut-il un Mac cloud / OpenClaw avant OpenHuman ?
Non. Installez OpenHuman d’abord en local. Ne considérez les options always-on de la section 11 que si vous avez besoin d’exploitation canal 7×24.
Optionnel : si vous avez besoin d’un agent pendant que vous êtes hors ligne
La plupart des lecteurs peuvent s’arrêter à la section 10. Si le troisième parcours de la section 11 — un Mac cloud dédié — correspond à votre façon de travailler, vous pouvez consulter les specs Mac cloud Hashvps. Ce choix est indépendant du fait qu’OpenHuman reste sur le portable.